
[ad_1]
Trong bối cảnh phát triển nhanh chóng của AI sáng tạo (GenAI), các nhà khoa học dữ liệu và nhà xây dựng AI không ngừng tìm kiếm các công cụ mạnh mẽ để tạo ra các ứng dụng đổi mới bằng cách sử dụng Mô hình ngôn ngữ lớn (LLM). DataRobot đã giới thiệu một bộ số liệu đánh giá, kiểm tra và đánh giá LLM nâng cao trong Playground của họ, cung cấp các khả năng độc đáo khiến nó khác biệt với các nền tảng khác.
Các số liệu này, bao gồm độ trung thực, tính chính xác, trích dẫn, Rouge-1, chi phí và độ trễ, cung cấp một cách tiếp cận toàn diện và tiêu chuẩn hóa để xác thực chất lượng và hiệu suất của các ứng dụng GenAI. Bằng cách tận dụng các số liệu này, khách hàng và nhà xây dựng AI có thể phát triển các giải pháp GenAI đáng tin cậy, hiệu quả và có giá trị cao với độ tin cậy cao hơn, đẩy nhanh thời gian tiếp thị và đạt được lợi thế cạnh tranh. Trong bài đăng trên weblog này, chúng tôi sẽ đi sâu vào các số liệu này và khám phá cách chúng có thể giúp bạn khai thác toàn bộ tiềm năng của LLM trong nền tảng DataRobot.
Khám phá các số liệu đánh giá toàn diện
Sân chơi của DataRobot cung cấp một bộ số liệu đánh giá toàn diện cho phép người dùng đánh giá, so sánh hiệu suất và xếp hạng các thử nghiệm Thế hệ tăng cường truy xuất (RAG) của họ. Các số liệu này bao gồm:
- Sự trung thành: Số liệu này đánh giá mức độ chính xác của các phản hồi do LLM tạo ra phản ánh dữ liệu có nguồn gốc từ cơ sở dữ liệu vectơ, đảm bảo độ tin cậy của thông tin.
- Tính đúng đắn: Bằng cách so sánh các phản hồi được tạo ra với sự thật cơ bản, thước đo độ chính xác sẽ đánh giá độ chính xác của kết quả đầu ra của LLM. Điều này đặc biệt có giá trị đối với các ứng dụng đòi hỏi độ chính xác cao, chẳng hạn như trong lĩnh vực chăm sóc sức khỏe, tài chính hoặc pháp lý, cho phép khách hàng tin tưởng vào thông tin do ứng dụng GenAI cung cấp.
- Trích dẫn: Số liệu này theo dõi các tài liệu được LLM truy xuất khi nhắc cơ sở dữ liệu vectơ, cung cấp thông tin chi tiết về các nguồn được sử dụng để tạo phản hồi. Nó giúp người dùng đảm bảo rằng ứng dụng của họ đang tận dụng các nguồn thích hợp nhất, nâng cao mức độ liên quan và độ tin cậy của nội dung được tạo ra. Các mô hình bảo vệ của Playground có thể hỗ trợ xác minh chất lượng và mức độ liên quan của các trích dẫn được LLM sử dụng.
- Đỏ-1: Số liệu Rouge-1 tính toán sự chồng chéo của unigram (mỗi từ) giữa phản hồi được tạo và tài liệu được truy xuất từ cơ sở dữ liệu vectơ, cho phép người dùng đánh giá mức độ liên quan của nội dung được tạo.
- Chi phí và độ trễ: Chúng tôi cũng cung cấp số liệu để theo dõi chi phí và độ trễ liên quan đến việc chạy LLM, cho phép người dùng tối ưu hóa thử nghiệm của họ để đạt hiệu quả và tiết kiệm chi phí. Các số liệu này giúp các tổ chức tìm ra sự cân bằng phù hợp giữa hiệu suất và hạn chế về ngân sách, đảm bảo tính khả thi của việc triển khai các ứng dụng GenAI trên quy mô lớn.
- Mô hình bảo vệ: Nền tảng của chúng tôi cho phép người dùng áp dụng các mô hình bảo vệ từ Cơ quan đăng ký DataRobot hoặc các mô hình tùy chỉnh để đánh giá phản hồi LLM. Các mô hình như máy dò độc tính và PII có thể được thêm vào sân chơi để đánh giá từng đầu ra LLM. Điều này cho phép dễ dàng thử nghiệm các mô hình bảo vệ dựa trên phản hồi LLM trước khi triển khai vào sản xuất.
Thử nghiệm hiệu quả
Sân chơi của DataRobot trao quyền cho khách hàng và nhà xây dựng AI thử nghiệm thoải mái với các LLM khác nhau, chiến lược phân chia, phương pháp nhúng và phương pháp nhắc nhở. Các số liệu đánh giá đóng một vai trò quan trọng trong việc giúp người dùng điều hướng hiệu quả quá trình thử nghiệm này. Bằng cách cung cấp một bộ số liệu đánh giá được tiêu chuẩn hóa, DataRobot cho phép người dùng dễ dàng so sánh hiệu suất của các thử nghiệm và cấu hình LLM khác nhau. Điều này cho phép khách hàng và nhà xây dựng AI đưa ra quyết định dựa trên dữ liệu khi chọn phương pháp tốt nhất cho trường hợp sử dụng cụ thể của họ, tiết kiệm thời gian và tài nguyên trong quy trình.
Ví dụ: bằng cách thử nghiệm các chiến lược phân đoạn hoặc phương pháp nhúng khác nhau, người dùng đã có thể cải thiện đáng kể độ chính xác và mức độ phù hợp của các ứng dụng GenAI của họ trong các tình huống thực tế. Mức độ thử nghiệm này rất quan trọng để phát triển các giải pháp GenAI hiệu suất cao phù hợp với yêu cầu cụ thể của ngành.
Tối ưu hóa và phản hồi của người dùng
Các số liệu đánh giá trong Playground hoạt động như một công cụ có giá trị để đánh giá hiệu suất của các ứng dụng GenAI. Bằng cách phân tích các số liệu như Rouge-1 hoặc trích dẫn, khách hàng và nhà xây dựng AI có thể xác định các lĩnh vực mà mô hình của họ có thể được cải thiện, chẳng hạn như nâng cao mức độ liên quan của các phản hồi được tạo ra hoặc đảm bảo rằng ứng dụng đang tận dụng các nguồn thích hợp nhất từ cơ sở dữ liệu vectơ. Các số liệu này cung cấp một cách tiếp cận định lượng để đánh giá chất lượng của các phản hồi được tạo ra.
Ngoài các số liệu đánh giá, Sân chơi của DataRobot cho phép người dùng cung cấp phản hồi trực tiếp về các phản hồi được tạo thông qua xếp hạng thích/không thích. Phản hồi của người dùng này là phương pháp chính để tạo tập dữ liệu tinh chỉnh. Người dùng có thể xem lại các phản hồi do LLM tạo ra và bỏ phiếu về chất lượng cũng như mức độ liên quan của chúng. Sau đó, các phản hồi được bình chọn nâng cao sẽ được sử dụng để tạo tập dữ liệu nhằm tinh chỉnh ứng dụng GenAI, cho phép ứng dụng học hỏi từ sở thích của người dùng và tạo ra các phản hồi chính xác và phù hợp hơn trong tương lai. Điều này có nghĩa là người dùng có thể thu thập nhiều phản hồi cần thiết để tạo tập dữ liệu tinh chỉnh toàn diện phản ánh sở thích và yêu cầu của người dùng trong thế giới thực.
Bằng cách kết hợp các số liệu đánh giá và phản hồi của người dùng, khách hàng và nhà xây dựng AI có thể đưa ra quyết định dựa trên dữ liệu để tối ưu hóa các ứng dụng GenAI của họ. Họ có thể sử dụng các số liệu này để xác định các phản hồi có hiệu suất cao và đưa chúng vào tập dữ liệu tinh chỉnh, đảm bảo rằng mô hình học hỏi từ các ví dụ tốt nhất. Quá trình đánh giá, phản hồi và tinh chỉnh lặp đi lặp lại này cho phép các tổ chức liên tục cải tiến các ứng dụng GenAI của họ và mang lại trải nghiệm chất lượng cao, lấy người dùng làm trung tâm.
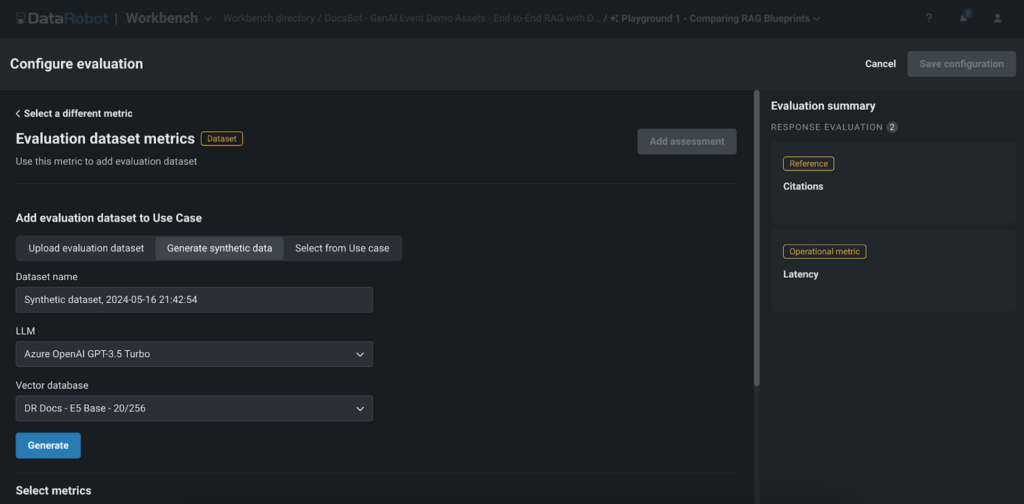
Tạo dữ liệu tổng hợp để đánh giá nhanh
Một trong những tính năng nổi bật của DataRobot’s Playground là tạo dữ liệu tổng hợp để đánh giá theo lời nhắc và câu trả lời. Tính năng này cho phép người dùng tạo các cặp câu hỏi và câu trả lời dựa trên cơ sở dữ liệu vectơ của người dùng một cách nhanh chóng và dễ dàng, cho phép họ đánh giá kỹ lưỡng hiệu suất của các thử nghiệm RAG mà không cần tạo dữ liệu thủ công.
Việc tạo dữ liệu tổng hợp mang lại một số lợi ích chính:
- Tiết kiệm thời gian: Tạo bộ dữ liệu lớn theo cách thủ công có thể tốn thời gian. Quá trình tạo dữ liệu tổng hợp của DataRobot tự động hóa quy trình này, tiết kiệm thời gian và tài nguyên quý giá, đồng thời cho phép khách hàng và nhà xây dựng AI nhanh chóng tạo nguyên mẫu và thử nghiệm các ứng dụng GenAI của họ.
- Khả năng mở rộng: Với khả năng tạo ra hàng nghìn cặp câu hỏi và câu trả lời, người dùng có thể kiểm tra kỹ lưỡng các thử nghiệm RAG của mình và đảm bảo tính mạnh mẽ trong nhiều tình huống. Phương pháp thử nghiệm toàn diện này giúp khách hàng và nhà xây dựng AI cung cấp các ứng dụng chất lượng cao, đáp ứng nhu cầu và mong đợi của người dùng cuối.
- Đánh giá chất lượng: Bằng cách so sánh các phản hồi được tạo với dữ liệu tổng hợp, người dùng có thể dễ dàng đánh giá chất lượng và độ chính xác của ứng dụng GenAI của họ. Điều này giúp tăng tốc thời gian tạo ra giá trị cho các ứng dụng GenAI, cho phép các tổ chức đưa các giải pháp đổi mới của mình ra thị trường nhanh hơn và đạt được lợi thế cạnh tranh trong các ngành tương ứng.
Điều quan trọng cần lưu ý là mặc dù dữ liệu tổng hợp cung cấp một cách nhanh chóng và hiệu quả để đánh giá các ứng dụng GenAI nhưng không phải lúc nào nó cũng có thể nắm bắt được toàn bộ sự phức tạp và sắc thái của dữ liệu trong thế giới thực. Do đó, điều quan trọng là sử dụng dữ liệu tổng hợp kết hợp với phản hồi thực của người dùng và các phương pháp đánh giá khác để đảm bảo tính mạnh mẽ và hiệu quả của ứng dụng GenAI.
Phần kết luận
Các số liệu đánh giá, kiểm tra và đánh giá LLM nâng cao của DataRobot trong Playground cung cấp cho khách hàng và nhà xây dựng AI một bộ công cụ mạnh mẽ để tạo ra các ứng dụng GenAI chất lượng cao, đáng tin cậy và hiệu quả. Bằng cách cung cấp các số liệu đánh giá toàn diện, khả năng thử nghiệm và tối ưu hóa hiệu quả, tích hợp phản hồi của người dùng và tạo dữ liệu tổng hợp để đánh giá nhanh chóng, DataRobot trao quyền cho người dùng khai thác toàn bộ tiềm năng của LLM và mang lại kết quả có ý nghĩa.
Với sự tự tin ngày càng tăng về hiệu suất mô hình, thời gian tạo ra giá trị nhanh hơn và khả năng tinh chỉnh ứng dụng của mình, khách hàng và nhà xây dựng AI có thể tập trung vào việc cung cấp các giải pháp sáng tạo giúp giải quyết các vấn đề trong thế giới thực và tạo ra giá trị cho người dùng cuối của họ. Sân chơi của DataRobot, với các số liệu đánh giá nâng cao và các tính năng độc đáo, là nhân tố thay đổi cuộc chơi trong bối cảnh GenAI, cho phép các tổ chức vượt qua ranh giới của những gì có thể với Mô hình ngôn ngữ lớn.
Đừng bỏ lỡ cơ hội tối ưu hóa các dự án của bạn với nền tảng đánh giá và thử nghiệm LLM tiên tiến nhất hiện có. Thăm nom Sân chơi của DataRobot ngay bây giờ và bắt đầu hành trình xây dựng các ứng dụng GenAI ưu việt thực sự nổi bật trong bối cảnh AI cạnh tranh.
Giới thiệu về tác giả

Nathaniel Daly là Giám đốc sản phẩm cấp cao tại DataRobot, tập trung vào AutoML và các sản phẩm chuỗi thời gian. Anh ấy tập trung vào việc mang lại những tiến bộ trong khoa học dữ liệu cho người dùng để họ có thể tận dụng giá trị này để giải quyết các vấn đề kinh doanh trong thế giới thực. Ông có bằng Toán học của Đại học California, Berkeley.
[ad_2]
Source link