
[ad_1]
Giới thiệu
Một trong những điều khó khăn nhất khi tạo ra các mô hình mạnh mẽ trong học máy là thử nghiệm nhiều cấp độ. Tối ưu hóa siêu tham số—điều chỉnh các cài đặt đó để đạt được điều gì đó không quá tệ—có thể là phần quan trọng nhất của tất cả. Trong bài đăng weblog này, với đầy đủ các đoạn mã, chúng tôi sẽ đề cập đến ý nghĩa của điều này và cách thực hiện.
Tổng quan
- Nhận ra tầm quan trọng của siêu tham số trong các mô hình học máy.
- Tìm hiểu các phương pháp tối ưu hóa siêu tham số khác nhau, chẳng hạn như điều chỉnh thủ công, tìm kiếm lưới, tìm kiếm ngẫu nhiên, tối ưu hóa Bayes và tối ưu hóa dựa trên độ dốc.
- Triển khai các kỹ thuật tối ưu hóa siêu tham số với các thư viện phổ biến như scikit-learn và scikit-optimize
- Tìm hiểu cách chọn chiến lược tối ưu hóa phù hợp tùy thuộc vào độ phức tạp của mô hình, chiều không gian tìm kiếm hoặc tài nguyên tính toán có sẵn
Bắt đầu với việc tối ưu hóa cho siêu tham số
Để bắt đầu, chúng ta cần hiểu siêu tham số. Trong mô hình học máy, chúng tôi quyết định các cài đặt này trước khi bắt đầu đào tạo. Họ kiểm soát các khía cạnh như kiến trúc mạng và số lượng lớp. Chúng cũng ảnh hưởng đến cách mô hình học dữ liệu. Ví dụ: khi sử dụng phương pháp giảm độ dốc, siêu tham số sẽ bao gồm tốc độ học. Sức mạnh chính quy hóa cũng có thể đạt được các mục tiêu tương tự nhưng thông qua các phương tiện hoàn toàn khác nhau.
Tầm quan trọng của việc tối ưu hóa siêu tham số
Sẽ không có gì ngạc nhiên khi việc đặt các siêu tham số này có ý nghĩa rất lớn đối với kết quả cuối cùng của bạn. Bạn biết vấn đề về trang bị thiếu và trang bị quá mức, phải không? Chà, nếu không, hãy nghĩ lại thời điểm Winamp có giao diện; những người mẫu không đủ sức khỏe không thể tận dụng tất cả thông tin có sẵn, trong khi những người thừa sức không biết họ đã được đào tạo về điều gì. Vì vậy, chúng tôi đang cố gắng đạt được một số tình huống Goldilocks (tức là vừa phải) trong đó các tham số của chúng tôi khái quát hóa tốt trên các ví dụ chưa thấy mà không hy sinh quá nhiều hiệu suất trên dữ liệu đã biết.
Có nhiều cách để tối ưu hóa siêu tham số, bao gồm điều chỉnh thủ công và phương pháp tự động. Dưới đây là một số kỹ thuật thường được sử dụng:
- Điều chỉnh thủ công: Phương pháp này yêu cầu thử thủ công các kết hợp siêu tham số khác nhau và đánh giá hiệu suất của mô hình. Mặc dù đơn giản nhưng có thể mất quá nhiều thời gian và tỏ ra không hiệu quả, đặc biệt đối với các mô hình có nhiều siêu tham số.
- Tìm kiếm lưới: Tìm kiếm lưới là một đánh giá toàn diện về tất cả các kết hợp siêu tham số có thể có trong một phạm vi được chỉ định. Mặc dù toàn diện nhưng nó có thể tốn kém về mặt tính toán, đặc biệt đối với không gian tìm kiếm nhiều chiều.
- Tìm kiếm ngẫu nhiên: Không giống như thử mọi kết hợp, tìm kiếm ngẫu nhiên chọn ngẫu nhiên các giá trị siêu tham số từ một phân phối được chỉ định. Nó có thể hiệu quả hơn tìm kiếm dạng lưới, đặc biệt là với không gian rộng.
- Tối ưu hóa Bayes: Tối ưu hóa Bayes liên quan đến việc xây dựng một mô hình xác suất nhằm thúc đẩy việc tìm kiếm hướng tới các siêu tham số tối ưu. Nó kiểm tra các lĩnh vực quan tâm trong khi bỏ qua những lĩnh vực không có tiềm năng trong không gian tìm kiếm một cách thông minh.
- Tối ưu hóa dựa trên độ dốc: Điều này coi siêu tham số là các tham số bổ sung có thể được cải thiện bằng cách sử dụng các phương pháp dựa trên độ dốc (ví dụ: giảm dần độ dốc ngẫu nhiên). Về cơ bản, nó có hiệu quả đối với các siêu tham số có thể phân biệt được như tốc độ học tập
Sau khi đề cập đến các khía cạnh lý thuyết, chúng ta hãy xem xét một số ví dụ mã để cho thấy cách tối ưu hóa siêu tham số có thể được thực hiện trên thực tế. Bài đăng trên weblog này sẽ sử dụng Python với thư viện scikit-learncung cấp nhiều công cụ khác nhau để điều chỉnh siêu tham số.
Ví dụ 1: Tìm kiếm lưới cho hồi quy logistic
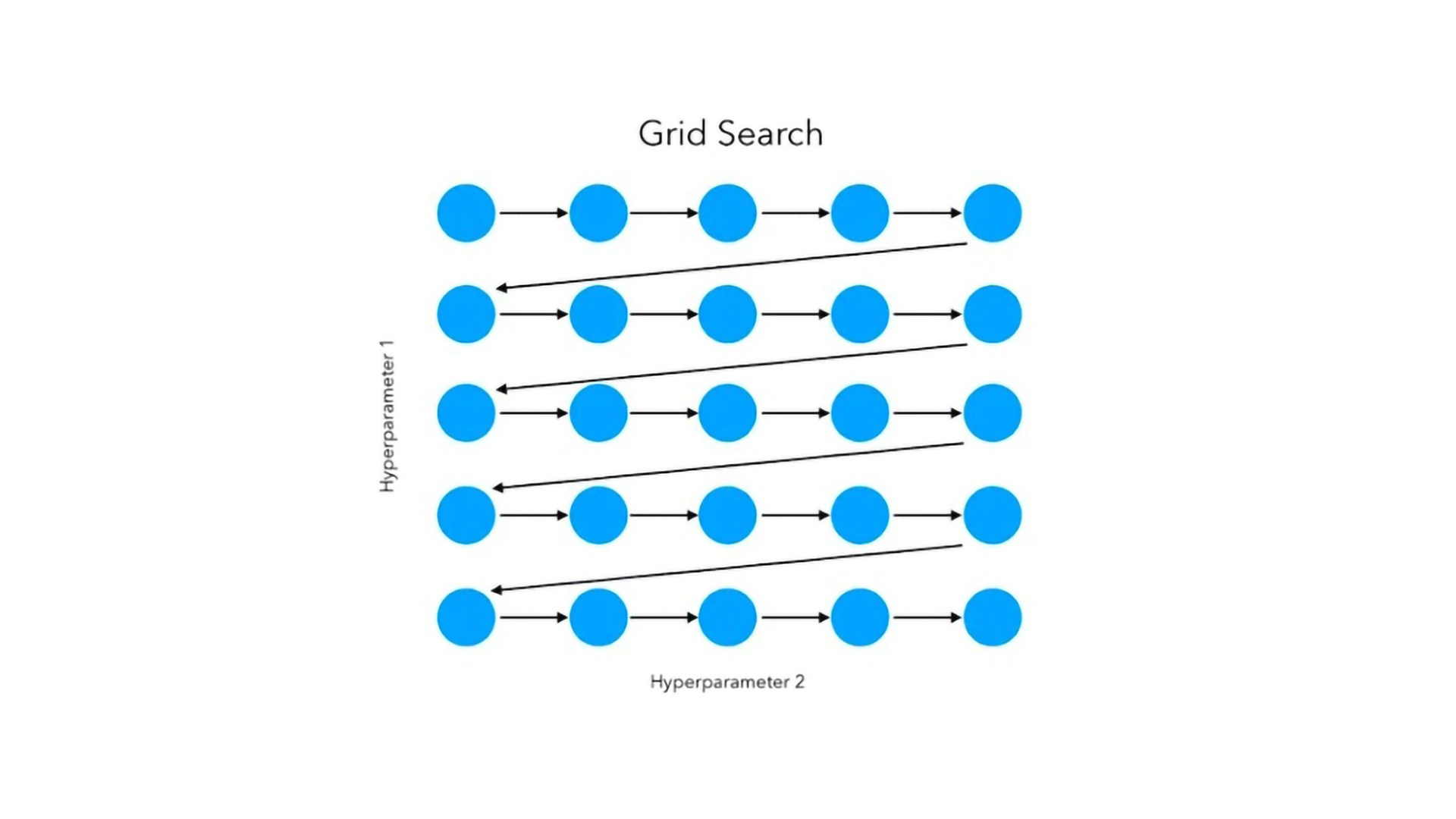
Giả sử rằng mô hình hồi quy logistic cần tối ưu hóa cường độ chính quy hóa (C) cùng với loại hình phạt (hình phạt), thì nó có thể được thực hiện bằng tìm kiếm lưới, trong đó tất cả các kết hợp có thể có của hai siêu tham số này đều được thử cho đến khi tìm thấy tham số thích hợp nhất.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# Outline the hyperparameter grid
param_grid = {
'C': (0.001, 0.01, 0.1, 1, 10, 100),
'penalty': ('l1', 'l2')
}
# Create the logistic regression mannequin
mannequin = LogisticRegression()
# Carry out grid search
grid_search = GridSearchCV(mannequin, param_grid, cv=5, scoring='accuracy')
grid_search.match(X_train, y_train)
# Get one of the best hyperparameters and the corresponding rating
best_params = grid_search.best_params_
best_score = grid_search.best_score_
print(f"Finest hyperparameters: {best_params}")
print(f"Finest accuracy rating: {best_score}")Trong ví dụ này, chúng tôi xác định một lưới các giá trị siêu tham số cho cường độ chính quy hóa (C) và loại hình phạt (hình phạt). Sau đó chúng tôi sử dụng lớp `GridSearchCV` từ scikit-tìm hiểu để thực hiện tìm kiếm toàn diện trên lưới được chỉ định, đánh giá hiệu suất của mô hình bằng cách sử dụng xác thực chéo 5 lần và độ chính xác làm thước đo tính điểm. Cuối cùng, chúng tôi in các siêu tham số tốt nhất và điểm chính xác tương ứng.
Ví dụ 2: Tối ưu hóa Bayes cho bộ phân loại rừng ngẫu nhiên
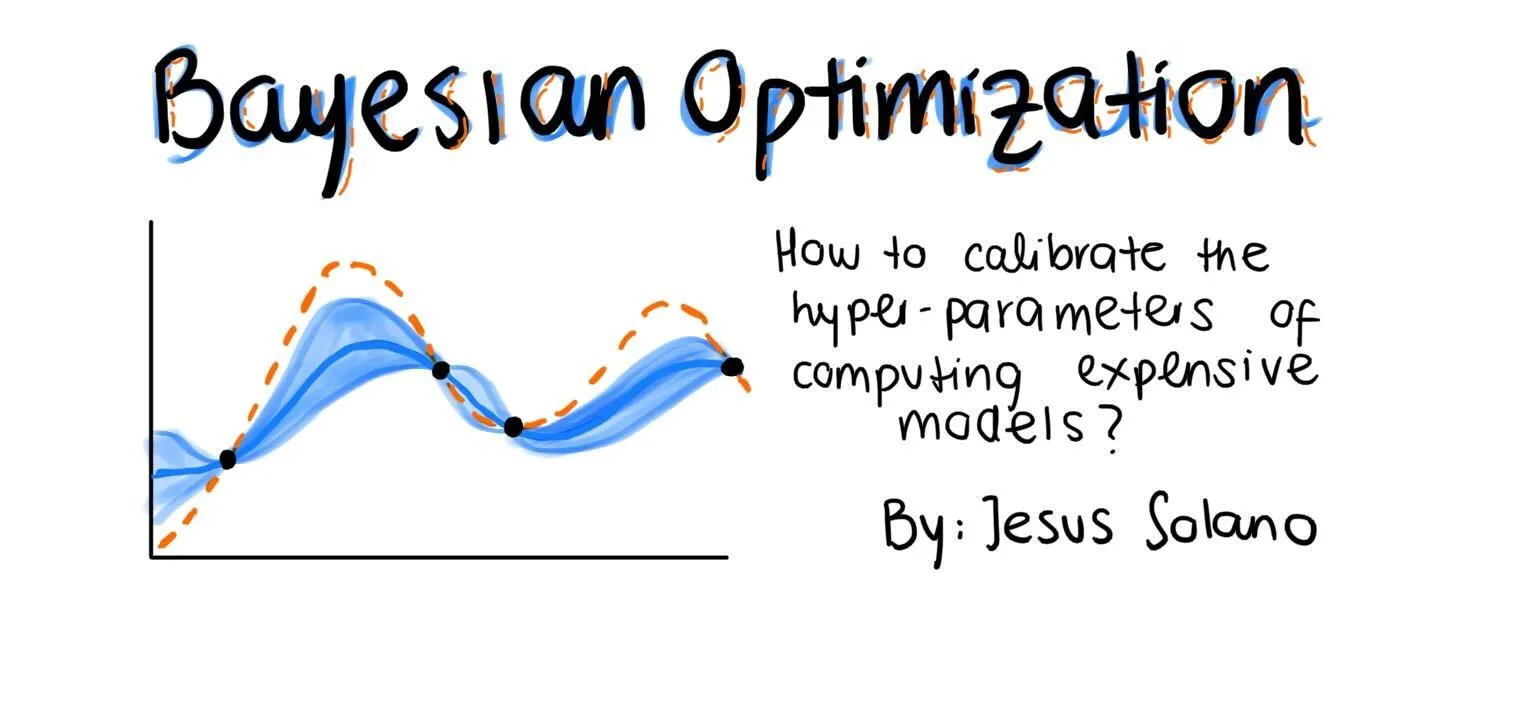
Tối ưu hóa Bayes là một kỹ thuật mạnh mẽ để điều chỉnh siêu tham số, đặc biệt khi xử lý các không gian tìm kiếm nhiều chiều hoặc khi việc đánh giá hàm mục tiêu rất tốn kém. Hãy xem cách chúng ta có thể sử dụng nó để tối ưu hóa bộ phân loại rừng ngẫu nhiên:
from sklearn.ensemble import RandomForestClassifier
from skopt import BayesSearchCV
# Outline the search house
search_spaces = {
'max_depth': (2, 20),
'max_features': (1, 'log2'),
'n_estimators': (10, 500),
'min_samples_split': (2, 20),
'min_samples_leaf': (1, 10)
}
# Create the random forest mannequin
mannequin = RandomForestClassifier(random_state=42)
# Carry out Bayesian optimization
bayes_search = BayesSearchCV(
mannequin,
search_spaces,
n_iter=100,
cv=3,
scoring='accuracy',
random_state=42
)
bayes_search.match(X_train, y_train)
# Get one of the best hyperparameters and the corresponding rating
best_params = bayes_search.best_params_
best_score = bayes_search.best_score_
print(f"Finest hyperparameters: {best_params}")
print(f"Finest accuracy rating: {best_score}")
Chẳng hạn, người ta có thể giới hạn độ sâu, số lượng tính năng và số lượng công cụ ước tính cũng như chỉ định các siêu tham số khác như các mẫu tối thiểu cần thiết để phân tách hoặc các nút lá trong bộ phân loại rừng ngẫu nhiên. Ở đây, chúng tôi sử dụng lớp “BayesSearchCV” từ thư viện tối ưu hóa bộ công cụ khoa học để tiến hành tối ưu hóa Bayes bằng cách thực hiện 100 lần lặp với xác thực chéo 3 lần bằng cách sử dụng chỉ số điểm chính xác, sau đó hiển thị các siêu tham số tốt nhất cùng với độ chính xác tương ứng của chúng.
Ví dụ 3: Tìm kiếm ngẫu nhiên với Optuna cho Bộ phân loại rừng ngẫu nhiên
Hãy khám phá cách sử dụng Optuna để thực hiện tìm kiếm ngẫu nhiên nhằm tối ưu hóa các siêu tham số của trình phân loại rừng ngẫu nhiên:
import optuna
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import cross_val_score
# Load the breast most cancers dataset
information = load_breast_cancer()
X, y = information.information, information.goal
# Outline the target operate to optimize
def goal(trial):
max_depth = trial.suggest_int('max_depth', 2, 32)
n_estimators = trial.suggest_int('n_estimators', 100, 1000)
max_features = trial.suggest_categorical('max_features', ('auto', 'sqrt', 'log2'))
rf = RandomForestClassifier(max_depth=max_depth,
n_estimators=n_estimators,
max_features=max_features,
random_state=42)
rating = cross_val_score(rf, X, y, cv=5, scoring='accuracy').imply()
return rating
# Create an Optuna research and optimize the target operate
research = optuna.create_study(route='maximize')
research.optimize(goal, n_trials=100)
# Print one of the best hyperparameters and the corresponding rating
print('Finest hyperparameters: ', research.best_params)
print('Finest accuracy rating: ', research.best_value)Các ví dụ trên chỉ là một số phương pháp và công cụ có thể được sử dụng khi thực hiện các tác vụ tối ưu hóa siêu tham số. Quá trình lựa chọn nên xem xét các yếu tố như độ phức tạp của mô hình, chiều không gian tìm kiếm hoặc tài nguyên tính toán sẵn có.
Bài học chính
1. Siêu tham số ảnh hưởng lớn đến mức độ hoạt động của mô hình học máy; do đó, việc chọn các giá trị thích hợp cho chúng có thể mang lại độ chính xác cao hơn và khả năng khái quát hóa tốt hơn.
2. Có nhiều cách khác nhau để tìm kiếm trong không gian siêu tham số, từ thủ công đến các kỹ thuật phức tạp hơn như tìm kiếm dạng lưới, tìm kiếm ngẫu nhiên, tối ưu hóa bayes hoặc giảm độ dốc nếu bạn cảm thấy thực sự thích phiêu lưu. Nhưng thay vào đó, hầu hết mọi người lại gắn bó với thứ gì đó đơn giản như vũ lực.
Mọi người nên nhớ lại rằng tối ưu hóa siêu tham số là một quá trình lặp đi lặp lại có thể yêu cầu giám sát và điều chỉnh liên tục các siêu tham số để đạt được hiệu suất tốt nhất.
Việc hiểu và áp dụng các kỹ thuật tối ưu hóa siêu tham số có thể khai thác toàn bộ tiềm năng của các mô hình học máy của bạn, điều này sẽ mang lại độ chính xác và tính khái quát cao hơn trên nhiều ứng dụng khác nhau, cùng nhiều thứ khác.
Phần kết luận
Điều chỉnh siêu tham số là một phần quan trọng để tạo ra các mô hình học máy thành công. Khi bạn khám phá lĩnh vực này một cách có hệ thống, việc tìm ra cách thiết lập tối ưu cho chúng sẽ giúp giải phóng những tiềm năng tiềm ẩn trong dữ liệu của bạn, dẫn đến khả năng khái quát hóa có độ chính xác cao hơn, cùng nhiều khả năng khác.
Cho dù bạn chọn điều chỉnh thủ công, tìm kiếm lưới, tìm kiếm ngẫu nhiên, tối ưu hóa Bayes hay phương pháp dựa trên độ dốc, việc hiểu các nguyên tắc và kỹ thuật tối ưu hóa siêu tham số sẽ giúp bạn tạo ra các giải pháp máy học mạnh mẽ và đáng tin cậy.
Câu hỏi thường gặp (FAQ)
A. Trước khi bắt đầu đào tạo, các giá trị cho các cài đặt này được quyết định trên cơ sở toàn mô hình; họ kiểm soát hành vi của nó, xây dựng kiến trúc và thực hiện quá trình học tập, chẳng hạn như nhưng không giới hạn ở tốc độ học tập, cường độ chính quy hóa, số lượng lớp ẩn và độ sâu tối đa cho cây quyết định.
A. Mặt khác, các siêu tham số được chọn kém có thể dẫn đến trang bị thiếu (mô hình quá đơn giản) hoặc trang bị quá mức (ghi nhớ dữ liệu huấn luyện mà không khái quát hóa). Do đó, ý tưởng chính đằng sau quá trình này là tìm ra sự kết hợp tốt nhất giúp tối đa hóa hiệu suất trên một nhiệm vụ nhất định trong số tất cả các cấu hình có thể có.
A. Các kỹ thuật phổ biến bao gồm điều chỉnh thủ công, tìm kiếm lưới, tìm kiếm ngẫu nhiên, tối ưu hóa Bayes và tối ưu hóa dựa trên độ dốc. Mỗi cái đều có điểm mạnh và điểm yếu và sự lựa chọn phụ thuộc vào các yếu tố như độ phức tạp của mô hình, chiều không gian tìm kiếm và tài nguyên tính toán sẵn có.
A. Câu trả lời phụ thuộc vào nhiều yếu tố khác nhau như mức độ đơn giản hay phức tạp của mô hình của bạn; kích thước của không gian mà qua đó chúng ta có thể khám phá các tham số mô hình đó là bao nhiêu (tức là số chiều); nhưng nó cũng phụ thuộc rất nhiều vào thời gian CPU/thời gian GPU nhưng sau đó nhiều khả năng họ đang nói về bộ nhớ RAM.
[ad_2]
Source link