
[ad_1]
Giới thiệu
Trong thời đại mà thông tin nằm trong tầm tay, khả năng đặt câu hỏi và nhận được câu trả lời chính xác đã trở nên vô cùng quan trọng. Hãy tưởng tượng có một hệ thống hiểu được sự phức tạp của ngôn ngữ và đưa ra phản hồi chính xác cho các truy vấn của bạn ngay lập tức. Bài viết này khám phá cách xây dựng một mô hình câu hỏi-trả lời mạnh mẽ như vậy bằng cách sử dụng Common Sentence Encoder và tập dữ liệu WikiQA. Bằng cách tận dụng các mô hình nhúng tiên tiến, chúng tôi hướng đến mục tiêu thu hẹp khoảng cách giữa sự tò mò của con người và trí thông minh của máy móc, tạo ra một tương tác liền mạch có thể cách mạng hóa cách chúng ta tìm kiếm và thu thập thông tin.
Mục tiêu học tập
- Nâng cao trình độ sử dụng các mô hình nhúng như Common Sentence Encoder để chuyển đổi dữ liệu văn bản thành biểu diễn vectơ đa chiều.
- Hiểu được những thách thức và chiến lược liên quan đến việc lựa chọn và tinh chỉnh các mô hình đã được đào tạo trước.
- Thông qua trải nghiệm thực hành, người học sẽ triển khai hệ thống trả lời câu hỏi sử dụng mô hình nhúng và độ tương đồng cosin.
- Hiểu các nguyên tắc đằng sau độ tương đồng cosin và ứng dụng của nó trong việc đo lường độ tương đồng giữa các biểu diễn văn bản vectơ.
Bài viết này được xuất bản như một phần của Blogathon về khoa học dữ liệu.
Tận dụng các mô hình nhúng trong NLP
Chúng tôi sẽ sử dụng các mô hình nhúng là một loại mô hình học máy được sử dụng rộng rãi trong xử lý ngôn ngữ tự nhiên (NLP). Phương pháp này chuyển đổi văn bản thành các định dạng số để nắm bắt ý nghĩa của chúng. Từ, cụm từ hoặc câu được chuyển đổi thành các vectơ số được gọi là nhúng. Các thuật toán sử dụng các nhúng này để hiểu và thao tác văn bản theo nhiều cách.
Hiểu về mô hình nhúng
Nhúng từ biểu diễn các từ một cách hiệu quả theo định dạng số dày đặc, trong đó các từ tương tự nhận được các mã hóa tương tự. Không giống như việc thiết lập thủ công các mã hóa này, mô hình học các nhúng dưới dạng các tham số có thể đào tạo được—các giá trị dấu phẩy động mà nó điều chỉnh trong quá trình đào tạo, tương tự như cách nó học các trọng số trong một lớp dày đặc. Nhúng có phạm vi từ 300 đối với các mô hình và tập dữ liệu nhỏ hơn đến các kích thước lớn hơn như 1024 đối với các mô hình và tập dữ liệu lớn hơn, cho phép chúng nắm bắt các mối quan hệ giữa các từ. Tính đa chiều cao hơn này cho phép nhúng mã hóa các mối quan hệ ngữ nghĩa chi tiết.
Trong sơ đồ nhúng từ, chúng tôi mô tả mỗi từ như một vectơ 4 chiều của các giá trị dấu phẩy động. Chúng ta có thể coi nhúng như một “bảng tra cứu”, nơi chúng ta lưu trữ vectơ dày đặc của mỗi từ sau khi đào tạo, cho phép mã hóa và truy xuất nhanh dựa trên biểu diễn vectơ tương ứng của nó.
Độ tương đồng ngữ nghĩa: Đo lường ý nghĩa trong văn bản
Độ tương đồng về mặt ngữ nghĩa là thước đo mức độ chặt chẽ của hai đoạn văn bản truyền tải cùng một ý nghĩa. Nó có giá trị vì nó giúp các hệ thống hiểu được nhiều cách khác nhau mà mọi người diễn đạt ý tưởng bằng ngôn ngữ mà không cần định nghĩa rõ ràng cho từng biến thể.
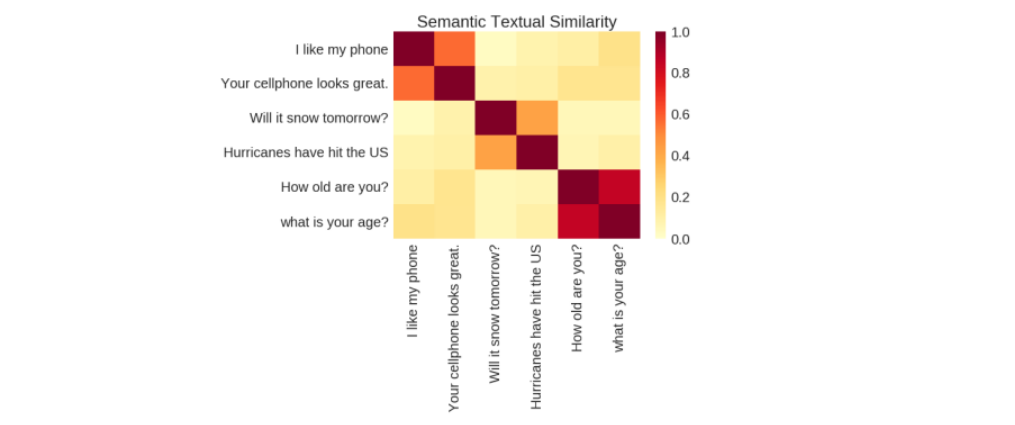
Common Sentence Encoder để xử lý văn bản nâng cao
Trong dự án này, chúng ta sẽ sử dụng Common Sentence Encoder, công cụ này chuyển đổi văn bản thành các vectơ có chiều cao hữu ích cho các tác vụ như phân loại văn bản, tính tương đồng về mặt ngữ nghĩa và phân cụm trong số những tác vụ khác. Công cụ này được tối ưu hóa để xử lý văn bản dài hơn các từ đơn lẻ. Công cụ này được đào tạo trên nhiều tập dữ liệu khác nhau và thích ứng với nhiều tác vụ ngôn ngữ tự nhiên khác nhau. Nhập văn bản tiếng Anh có độ dài thay đổi sẽ tạo ra một vectơ 512 chiều làm đầu ra.
Sau đây là ví dụ về đầu ra nhúng của 512 chiều cho mỗi câu:
!pip set up tensorflow tensorflow-hub
import tensorflow as tf
import tensorflow_hub as hub
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
sentences = (
"The short brown fox jumps over the lazy canine.",
"I'm a sentence for which I want to get its embedding"
)
embeddings = embed(sentences)
print(embeddings)
print(embeddings.numpy())Đầu ra:

Bộ mã hóa này sử dụng mạng trung bình sâu (DAN) để đào tạo, phân biệt với các mô hình nhúng cấp độ từ bằng cách tập trung vào việc hiểu ý nghĩa của chuỗi từ, không chỉ các từ riêng lẻ. Để biết thêm thông tin về nhúng văn bản, hãy tham khảo Tài liệu nhúng của TensorFlow. Các chi tiết kỹ thuật khác có thể được tìm thấy trong bài báo “Common Sentence Encoder” đây.
Mô-đun này xử lý trước dữ liệu nhập vào theo cách tốt nhất có thể, do đó bạn không cần phải xử lý trước dữ liệu trước khi áp dụng.

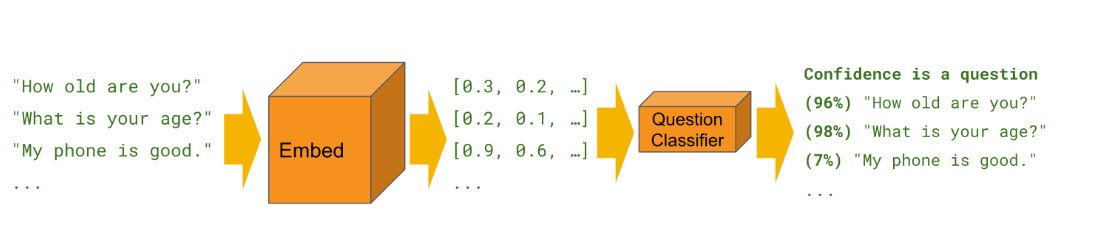
Các nhà phát triển đã đào tạo một phần Common Sentence Encoder với các tác vụ phân loại văn bản tùy chỉnh. Chúng ta có thể đào tạo các bộ phân loại này để thực hiện nhiều tác vụ phân loại khác nhau, thường với một lượng rất nhỏ các ví dụ được gắn nhãn.
Triển khai mã cho Trình tạo câu hỏi-trả lời
Bộ dữ liệu được sử dụng cho mã này là từ WikiQA Bộ dữ liệu .
import pandas as pd
import tensorflow_hub as hub #offers pre-trained fashions and modules just like the USE.
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# Load dataset (regulate the trail accordingly)
df = pd.read_csv('/content material/practice.csv')
questions = df('query').tolist()
solutions = df('reply').tolist()
# Load Common Sentence Encoder
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
# Compute embeddings
question_embeddings = embed(questions)
answer_embeddings = embed(solutions)
# Calculate similarity scores
similarity_scores = cosine_similarity(question_embeddings, answer_embeddings)
# Predict solutions
predicted_indices = np.argmax(similarity_scores, axis=1) # finds the index of the reply with the best similarity rating.
predictions = (solutions(idx) for idx in predicted_indices)
# Print questions and predicted solutions
for i, query in enumerate(questions):
print(f"Query: {query}")
print(f"Predicted Reply: {predictions(i)}n")

Hãy sửa đổi mã để đặt câu hỏi tùy chỉnh, in ra câu hỏi giống nhất và câu trả lời dự đoán:
def ask_question(new_question):
new_question_embedding = embed((new_question))
similarity_scores = cosine_similarity(new_question_embedding, question_embeddings)
most_similar_question_idx = np.argmax(similarity_scores)
most_similar_question = questions(most_similar_question_idx)
predicted_answer = solutions(most_similar_question_idx)
return most_similar_question, predicted_answer
# Instance utilization
new_question = "When was Apple Pc based?"
most_similar_question, predicted_answer = ask_question(new_question)
print(f"New Query: {new_question}")
print(f"Most Related Query: {most_similar_question}")
print(f"Predicted Reply: {predicted_answer}")Đầu ra:

Câu hỏi mới: Apple Pc được thành lập vào năm nào?
Câu hỏi tương tự nhất: Apple Pc được thành lập vào năm nào?
Câu trả lời dự đoán: Apple Inc., trước đây là Apple Pc, Inc., thiết kế, phát triển và bán đồ điện tử tiêu dùng, phần mềm máy tính và máy tính cá nhân. Tập đoàn đa quốc gia của Mỹ này có trụ sở chính tại Cupertino, California.
Lợi ích của việc sử dụng mô hình nhúng trong tác vụ NLP
- Nhiều mô hình nhúng, như Common Sentence Encoder, được đào tạo trước trên lượng dữ liệu lớn, giúp giảm nhu cầu đào tạo chuyên sâu trên các tập dữ liệu cụ thể và cho phép triển khai nhanh hơn, do đó tiết kiệm được tài nguyên tính toán.
- Bằng cách biểu diễn văn bản trong không gian đa chiều, hệ thống nhúng có thể nhận dạng và khớp các cụm từ có ngữ nghĩa tương tự, ngay cả khi chúng sử dụng các từ khác nhau như từ đồng nghĩa và câu hỏi diễn giải lại.
- Chúng ta có thể đào tạo nhiều mô hình nhúng để hoạt động với nhiều ngôn ngữ, giúp phát triển các hệ thống trả lời câu hỏi đa ngôn ngữ dễ dàng hơn.
- Hệ thống nhúng đơn giản hóa quá trình thiết kế tính năng cần thiết cho quy trình mô hình học máy bằng cách tự động học các tính năng từ dữ liệu.
Những thách thức trong Trình tạo câu hỏi-trả lời
- Việc lựa chọn mô hình được đào tạo trước phù hợp và tinh chỉnh các thông số cho các trường hợp sử dụng cụ thể có thể là một thách thức.
- Việc xử lý khối lượng dữ liệu lớn một cách hiệu quả trong các ứng dụng thời gian thực đòi hỏi phải tối ưu hóa cẩn thận và có thể rất khó khăn.
- Những sắc thái, chi tiết phức tạp và diễn giải sai ngữ cảnh trong ngôn ngữ có thể dẫn đến kết quả tạo ra không chính xác.
Phần kết luận
Nhúng mô hình do đó có thể cải thiện hệ thống trả lời câu hỏi. Việc chuyển đổi văn bản thành nhúng và tính toán điểm tương đồng giúp hệ thống xác định chính xác và dự đoán câu trả lời có liên quan cho câu hỏi của người dùng. Cách tiếp cận này tăng cường các trường hợp sử dụng mô hình nhúng trong các tác vụ liên quan đến NLP có sự tương tác của con người.
Chìa khóa học tập
- Các mô hình nhúng như Common Sentence Encoder cung cấp các công cụ để chuyển đổi văn bản thành dạng số.
- Sử dụng hệ thống trả lời câu hỏi dựa trên nhúng sẽ cải thiện tương tác của người dùng bằng cách đưa ra phản hồi chính xác và phù hợp.
- Chúng ta phải đối mặt với những thách thức như sự mơ hồ về mặt ngữ nghĩa, các truy vấn đa dạng và duy trì hiệu quả tính toán.
Các câu hỏi thường gặp
A. Các mô hình nhúng, như Common Sentence Encoder, chuyển văn bản thành các dạng số chi tiết được gọi là nhúng. Chúng giúp hệ thống hiểu và đưa ra câu trả lời chính xác cho các câu hỏi của người dùng.
A. Nhiều mô hình nhúng có thể hoạt động với nhiều ngôn ngữ. Chúng ta có thể sử dụng chúng trong các hệ thống trả lời câu hỏi bằng nhiều ngôn ngữ khác nhau, khiến các hệ thống này rất linh hoạt.
A. Hệ thống nhúng có khả năng nhận dạng và ghép các cụm từ như từ đồng nghĩa và hiểu các loại nhiệm vụ ngôn ngữ khác nhau.
A. Việc lựa chọn đúng mô hình và thiết lập mô hình cho các tác vụ cụ thể có thể rất khó khăn. Ngoài ra, việc quản lý nhanh khối lượng dữ liệu lớn, đặc biệt là trong các tình huống thời gian thực, cần phải có kế hoạch cẩn thận.
A. Bằng cách chuyển văn bản thành nhúng và kiểm tra mức độ giống nhau của chúng, các mô hình nhúng có thể đưa ra câu trả lời rất chính xác cho các câu hỏi của người dùng. Điều này làm cho người dùng hài lòng hơn vì họ nhận được câu trả lời phù hợp chính xác với những gì họ đã hỏi.
Các phương tiện truyền thông được trình bày trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định của Tác giả.
[ad_2]
Source link