
[ad_1]
Giới thiệu
Hãy tưởng tượng việc sàng lọc hàng ngàn bức ảnh để tìm ra một bức ảnh hoàn hảo—thật tẻ nhạt, phải không? Bây giờ, hãy hình dung một hệ thống có thể thực hiện việc này trong vài giây, ngay lập tức cung cấp cho bạn những hình ảnh giống nhau nhất dựa trên truy vấn của bạn. Trong bài viết này, bạn sẽ khám phá thế giới hấp dẫn của tìm kiếm độ tương đồng hình ảnh, nơi chúng ta sẽ chuyển đổi ảnh thành các vectơ số bằng mô hình VGG16 mạnh mẽ. Với các vectơ này được lập chỉ mục bởi FAISS, một công cụ được thiết kế để định vị nhanh chóng và chính xác các mục tương tự, bạn sẽ học cách xây dựng một hệ thống tìm kiếm hợp lý và hiệu quả. Cuối cùng, bạn sẽ không chỉ nắm bắt được phép thuật đằng sau nhúng vectơ và FAISS mà còn có được các kỹ năng thực hành để triển khai hệ thống truy xuất hình ảnh tốc độ cao của riêng mình.
Mục tiêu học tập
- Hiểu cách nhúng vector chuyển đổi dữ liệu phức tạp thành biểu diễn số để phân tích.
- Tìm hiểu vai trò của VGG16 trong việc tạo nhúng hình ảnh và ứng dụng của nó trong tìm kiếm độ tương đồng của hình ảnh.
- Tìm hiểu sâu hơn về FAISS và khả năng lập chỉ mục và truy xuất nhanh các vectơ tương tự.
- Phát triển kỹ năng triển khai hệ thống tìm kiếm điểm tương đồng của hình ảnh bằng VGG16 và FAISS.
- Khám phá những thách thức và giải pháp liên quan đến dữ liệu đa chiều và tìm kiếm điểm tương đồng hiệu quả.
Bài viết này được xuất bản như một phần của Blogathon về khoa học dữ liệu.
Hiểu về nhúng vector
Nhúng vector là một cách để biểu diễn dữ liệu như hình ảnh, văn bản hoặc âm thanh dưới dạng vector số. Trong biểu diễn này, các mục tương tự được đặt gần nhau trong không gian nhiều chiều, giúp máy tính nhanh chóng tìm và so sánh thông tin liên quan.
Ưu điểm của nhúng vector
Bây giờ chúng ta hãy cùng khám phá chi tiết những lợi thế của nhúng vector.
- Nhúng vectơ tiết kiệm thời gian vì khoảng cách giữa các vectơ có thể được tính toán nhanh chóng.
- Các nhúng xử lý tập dữ liệu lớn một cách hiệu quả, giúp chúng có khả năng mở rộng và phù hợp với các ứng dụng dữ liệu lớn.
- Dữ liệu nhiều chiều, chẳng hạn như hình ảnh, có thể biểu diễn không gian ít chiều hơn mà không làm mất thông tin quan trọng. Biểu diễn này đơn giản hóa lưu trữ và tăng cường hiệu quả không gian. Nó nắm bắt ý nghĩa ngữ nghĩa giữa các mục dữ liệu, dẫn đến kết quả chính xác hơn trong các tác vụ đòi hỏi sự hiểu biết theo ngữ cảnh, chẳng hạn như NLP và nhận dạng hình ảnh.
- Nhúng vector rất linh hoạt vì chúng có thể được áp dụng cho các loại dữ liệu khác nhau
- Có sẵn các cơ sở dữ liệu vector và nhúng được đào tạo trước giúp giảm nhu cầu đào tạo dữ liệu mở rộng, do đó chúng ta tiết kiệm được tài nguyên tính toán.
- Theo truyền thống, các kỹ thuật thiết kế tính năng đòi hỏi phải tạo và lựa chọn tính năng thủ công, trong khi nhúng tự động hóa quy trình thiết kế tính năng bằng cách học các tính năng từ dữ liệu.
- Các nhúng có khả năng thích ứng tốt hơn với các đầu vào mới so với các mô hình dựa trên quy tắc.
- Các phương pháp dựa trên đồ thị cũng nắm bắt được các mối quan hệ phức tạp nhưng đòi hỏi các thuật toán và cấu trúc dữ liệu phức tạp hơn, việc nhúng ít tốn kém hơn về mặt tính toán.
VGG16 là gì?
Chúng tôi sẽ sử dụng VGG16 để tính toán nhúng hình ảnh của chúng tôi. VGG16 là một Convolutional Mạng lưới nơ-ron đây là thuật toán phát hiện và phân loại đối tượng. 16 tượng trưng cho 16 lớp có trọng số có thể học được trong mạng.
Bắt đầu với một hình ảnh đầu vào và thay đổi kích thước thành 224×224 pixel với ba kênh màu. Bây giờ, chúng được chuyển đến các lớp tích chập giống như một loạt các bộ lọc xem xét các phần nhỏ của hình ảnh. Mỗi bộ lọc ở đây sẽ chụp các đặc điểm khác nhau như các cạnh, màu sắc, kết cấu, v.v. VGG16 sử dụng các bộ lọc 3X3, nghĩa là chúng xem xét diện tích pixel 3X3 tại một thời điểm. Có 13 lớp tích chập trong VGG16. Tiếp theo là Hàm kích hoạt (ReLU) viết tắt của Đơn vị tuyến tính chỉnh lưu và nó thêm tính phi tuyến tính vào mô hình, cho phép mô hình học các mẫu phức tạp hơn.
Tiếp theo là các lớp Pooling Layers giúp giảm kích thước của biểu diễn hình ảnh bằng cách lấy thông tin quan trọng nhất từ các mảng nhỏ, thu nhỏ hình ảnh trong khi vẫn giữ nguyên các đặc điểm quan trọng. VGG16 sử dụng các lớp pooling 2X2, nghĩa là nó giảm một nửa kích thước hình ảnh. Cuối cùng, Absolutely Linked Layer nhận đầu ra và sử dụng tất cả thông tin mà các lớp tích chập đã học được để đưa ra kết luận cuối cùng. Lớp đầu ra xác định lớp mà hình ảnh đầu vào có nhiều khả năng thuộc về nhất bằng cách tạo xác suất cho từng lớp bằng hàm softmax.

Đầu tiên tải mô hình sau đó sử dụng VGG16 với trọng số được đào tạo trước nhưng loại bỏ lớp cuối cùng cung cấp phân loại cuối cùng. Bây giờ thay đổi kích thước và xử lý trước các hình ảnh để phù hợp với yêu cầu của mô hình là 224 X 224 pixel và cuối cùng tính toán nhúng bằng cách truyền hình ảnh qua mô hình từ một trong các lớp được kết nối đầy đủ.
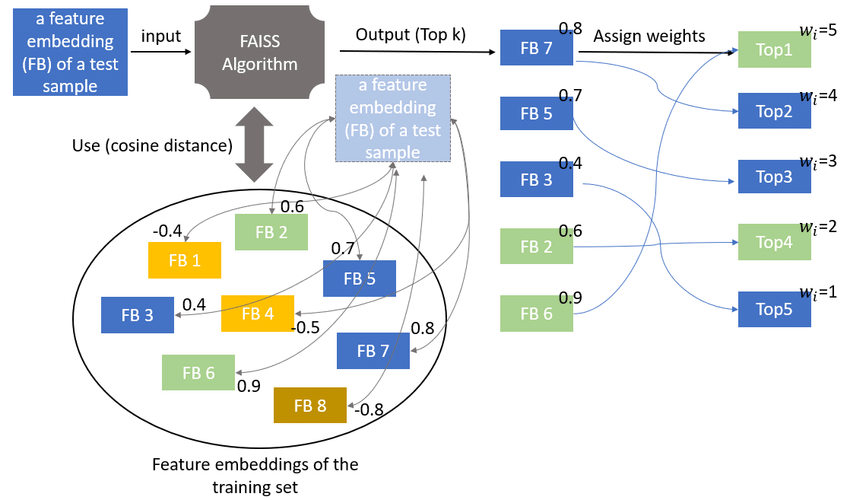
Sử dụng FAISS để lập chỉ mục
Fb AI Analysis đã phát triển Fb AI Similarity Search (FAISS) để tìm kiếm và nhóm các vectơ dày đặc một cách hiệu quả. FAISS vượt trội trong việc xử lý các tập dữ liệu quy mô lớn và nhanh chóng tìm thấy các mục tương tự với truy vấn.
Tìm kiếm tương đồng là gì?
FAISS xây dựng một chỉ mục trong RAM khi bạn cung cấp một vectơ có chiều (d_i). Chỉ mục này, một đối tượng có add phương pháp, lưu trữ vectơ (x_i), giả sử chiều cố định cho (x_i).
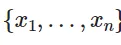
Sau khi cấu trúc được xây dựng khi một vectơ x mới được cung cấp trong chiều d, nó thực hiện thao tác sau. Tính toán argmin là thao tác tìm kiếm trên chỉ mục.
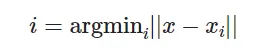
FAISS tìm các mục trong chỉ mục gần nhất với mục mới.
Ở đây || .|| biểu thị khoảng cách Euclid (L2). Độ gần được đo bằng khoảng cách Euclid.
Triển khai mã bằng cách sử dụng Vector Embeddings
Bây giờ chúng ta sẽ xem xét việc triển khai mã để phát hiện hình ảnh tương tự bằng cách nhúng vector.
Bước 1: Nhập thư viện
Nhập các thư viện cần thiết để xử lý hình ảnh, xử lý mô hình và tìm kiếm điểm tương đồng.
import cv2
import numpy as np
import faiss
import os
from keras.functions.vgg16 import VGG16, preprocess_input
from keras.preprocessing import picture
from keras.fashions import Mannequin
from google.colab.patches import cv2_imshowBước 2: Tải hình ảnh từ thư mục
Xác định một hàm để tải tất cả hình ảnh từ một thư mục được chỉ định và các thư mục con của nó.
# Load pictures from folder and subfolders
def load_images_from_folder(folder):
pictures = ()
image_paths = ()
for root, dirs, information in os.stroll(folder):
for file in information:
if file.endswith(('jpg', 'jpeg', 'png')):
img_path = os.path.be a part of(root, file)
img = cv2.imread(img_path)
if img is just not None:
pictures.append(img)
image_paths.append(img_path)
return pictures, image_pathsBước 3: Tải mô hình đã được đào tạo trước và xóa các lớp trên cùng
Tải mô hình VGG16 đã được đào tạo trước trên ImageNet và sửa đổi nó để nhúng đầu ra từ lớp ‘fc1’.
# Load pre-trained mannequin and take away high layers
base_model = VGG16(weights="imagenet")
mannequin = Mannequin(inputs=base_model.enter, outputs=base_model.get_layer('fc1').output)Bước 4: Tính toán nhúng bằng VGG16
Xác định hàm để tính toán nhúng hình ảnh bằng cách sử dụng mô hình VGG16 đã sửa đổi.
# Compute embeddings utilizing VGG16
def compute_embeddings(pictures)
embeddings = ()
for img in pictures:
img = cv2.resize(img, (224, 224))
img = picture.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = preprocess_input(img)
img_embedding = mannequin.predict(img)
embeddings.append(img_embedding.flatten())
return np.array(embeddings)Bước 5: Tạo chỉ mục FAISS
Xác định hàm để tạo chỉ mục FAISS từ các nhúng được tính toán.
def create_index(embeddings):
d = embeddings.form(1)
index = faiss.IndexFlatL2(d)
index.add(embeddings)
return indexBước 6: Tải hình ảnh và tính toán nhúng
Tải hình ảnh, tính toán nhúng của chúng và tạo chỉ mục FAISS.
pictures, image_paths = load_images_from_folder('pictures')
embeddings = compute_embeddings(pictures)
index = create_index(embeddings)Bước 7: Tìm kiếm hình ảnh tương tự
Xác định hàm để tìm kiếm những hình ảnh giống nhau nhất trong chỉ mục FAISS.
def search_similar_images(index, query_embedding, top_k=1):
D, I = index.search(query_embedding, top_k)
return IBước 8: Ví dụ sử dụng
Tải hình ảnh truy vấn, tính toán nhúng của hình ảnh đó và tìm kiếm các hình ảnh tương tự.
# Seek for comparable pictures
def search_similar_images(index, query_embedding, top_k=1):
D, I = index.search(query_embedding, top_k)
return IBước 9: Hiển thị kết quả
In chỉ mục và đường dẫn tệp của các hình ảnh tương tự.
print("Related pictures indices:", similar_images_indices)
for idx in similar_images_indices(0):
print(image_paths(idx))Bước 10: Hiển thị hình ảnh bằng cv2_imshow
Hiển thị hình ảnh truy vấn và hình ảnh tương tự nhất bằng cách sử dụng OpenCV cv2_imshow.
print("Question Picture")
cv2_imshow(query_image)
cv2.waitKey(0) # Anticipate a key press to shut the picture
for idx in similar_images_indices(0):
similar_image = cv2.imread(image_paths(idx))
print("Most Related Picture")
cv2_imshow(similar_image)
cv2.waitKey(0)
cv2.destroyAllWindows()

Tôi đã sử dụng tập dữ liệu hình ảnh Rau để triển khai mã, có thể tìm thấy tập dữ liệu tương tự đây.
Đối mặt những thách thức
- Việc lưu trữ các nhúng có chiều cao cho một số lượng lớn hình ảnh sẽ tiêu tốn một lượng bộ nhớ lớn.
- Việc tạo nhúng và thực hiện tìm kiếm tương tự có thể tốn nhiều tính toán
- Sự khác biệt về chất lượng, kích thước và định dạng hình ảnh có thể ảnh hưởng đến độ chính xác của nội dung nhúng.
- Việc tạo và cập nhật chỉ mục FAISS có thể tốn nhiều thời gian trong trường hợp có bộ dữ liệu rất lớn.
Phần kết luận
Chúng tôi đã khám phá việc tạo ra một hệ thống tìm kiếm sự tương đồng của hình ảnh bằng cách tận dụng các nhúng vector và FAISS (Fb AI Similarity Search). Chúng tôi bắt đầu bằng cách tìm hiểu các nhúng vector và vai trò của chúng trong việc biểu diễn hình ảnh dưới dạng các vector số, tạo điều kiện cho các tìm kiếm sự tương đồng hiệu quả. Sử dụng mô hình VGG16, chúng tôi đã tính toán các nhúng hình ảnh bằng cách xử lý và thay đổi kích thước hình ảnh để trích xuất các tính năng có ý nghĩa. Sau đó, chúng tôi đã tạo một chỉ mục FAISS để quản lý và tìm kiếm hiệu quả thông qua các nhúng này.
Cuối cùng, chúng tôi đã trình bày cách truy vấn chỉ mục này để tìm hình ảnh tương tự, nêu bật những lợi thế và thách thức khi làm việc với dữ liệu đa chiều và các kỹ thuật tìm kiếm tương tự. Cách tiếp cận này nhấn mạnh sức mạnh của việc kết hợp các mô hình học sâu với các phương pháp lập chỉ mục tiên tiến để nâng cao khả năng truy xuất và so sánh hình ảnh.
Những điểm chính
- Nhúng vector chuyển đổi dữ liệu phức tạp như hình ảnh thành các vector số để tìm kiếm sự tương đồng hiệu quả.
- Mô hình VGG16 trích xuất các đặc điểm có ý nghĩa từ hình ảnh, tạo ra các nhúng chi tiết để so sánh.
- Việc lập chỉ mục FAISS giúp tăng tốc tìm kiếm điểm tương đồng bằng cách quản lý và truy vấn hiệu quả các tập hợp nhúng hình ảnh lớn.
- Tìm kiếm hình ảnh tương tự tận dụng các kỹ thuật lập chỉ mục tiên tiến để nhanh chóng xác định và truy xuất các hình ảnh có thể so sánh được.
- Việc xử lý dữ liệu đa chiều đòi hỏi nhiều thách thức về sử dụng bộ nhớ và tài nguyên tính toán nhưng lại rất quan trọng để tìm kiếm điểm tương đồng hiệu quả.
Các câu hỏi thường gặp
A. Nhúng vector là biểu diễn số của các thành phần dữ liệu, chẳng hạn như hình ảnh, văn bản hoặc âm thanh. Chúng định vị các mục tương tự gần nhau trong không gian nhiều chiều, cho phép máy tính tìm kiếm và so sánh sự tương đồng hiệu quả.
A. Nhúng vector đơn giản hóa và tăng tốc việc tìm kiếm và so sánh các mục tương tự trong các tập dữ liệu lớn. Chúng cho phép tính toán hiệu quả khoảng cách giữa các điểm dữ liệu, khiến chúng trở nên lý tưởng cho các tác vụ yêu cầu tìm kiếm sự tương đồng nhanh chóng và hiểu biết theo ngữ cảnh.
A. FAISS, do Fb AI Analysis phát triển, tìm kiếm và nhóm các vector dày đặc một cách hiệu quả. Được thiết kế cho các tập dữ liệu quy mô lớn, FAISS nhanh chóng truy xuất các mục tương tự bằng cách tạo và tìm kiếm thông qua chỉ mục nhúng vector.
A. FAISS hoạt động bằng cách tạo chỉ mục từ các nhúng vector của dữ liệu của bạn. Khi bạn cung cấp một vector mới, FAISS sẽ tìm kiếm chỉ mục để tìm các vector gần nhất. Nó thường đo độ tương đồng bằng khoảng cách Euclidean (L2).
Các phương tiện truyền thông được trình bày trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định của Tác giả.
[ad_2]
Source link